






Briefing the Machines: Fixing the Structural Deficit in One Industry's Approach to GEO
- Alan Rambam

- 2 days ago
- 5 min read
The global public relations and communications industry have spent more than a century mastering how brands are perceived by humans. Agencies have built massive networks dedicated to managing narratives, pitching the media, securing editorial placements, and refining corporate messaging.
It is a multi-billion-dollar ecosystem built on narrative control—and traditional agencies do it better than anyone.
Fixing The Structural Deficit Crisis
But right now, a profound structural crisis is unfolding quietly in the background. The most influential voice describing your enterprise clients today is no longer a major publication, a tier-one journalist, or a paid influencer network. Despite their expertise, agencies are missing the most influential voice in today's evolving landscape.
It’s ChatGPT, Gemini, Perplexity, Claude, and the autonomous, agentic browsers—that is, web browsers enhanced by AI agents to independently take actions—being built on top of them.
Every single day, these artificial intelligence engines generate millions of critical first impressions for global brands with transaction-ready B2B and B2C consumers. They summarize corporate legacies, compare product lines with competitors, evaluate executives' reputations, and, most importantly, dictate who gets recommended.
Communications leaders have spent decades briefing the media and refining narratives for human audiences and they’ve extended this approach to GEO. This approach is incorrect it overlooks the audience that matters most—the machines.
Every day, AI engines quickly survey brand details, evaluate factors like reputation and product offerings, and decide which brands to recommend to consumers.
The machine is making the decision and to date no one has been briefing them –- we’ve changed that.
The Illusion of Consensus
Recently, major global agencies have introduced research advocating for Generative Engine Optimization (GEO)—a practice we deliver. Optimizing brand data to influence how generative AI models describe a company, but the difference is that they’re suggesting that brands must build an absolute "chorus of content" across earned, owned, and social media to win "independent corroboration" from large language models (LLMs), which are advanced AI systems trained to generate human-like text. I hear it non-stop some days.
The thesis sounds logical, but from an architecture standpoint, it has a massive execution gap.
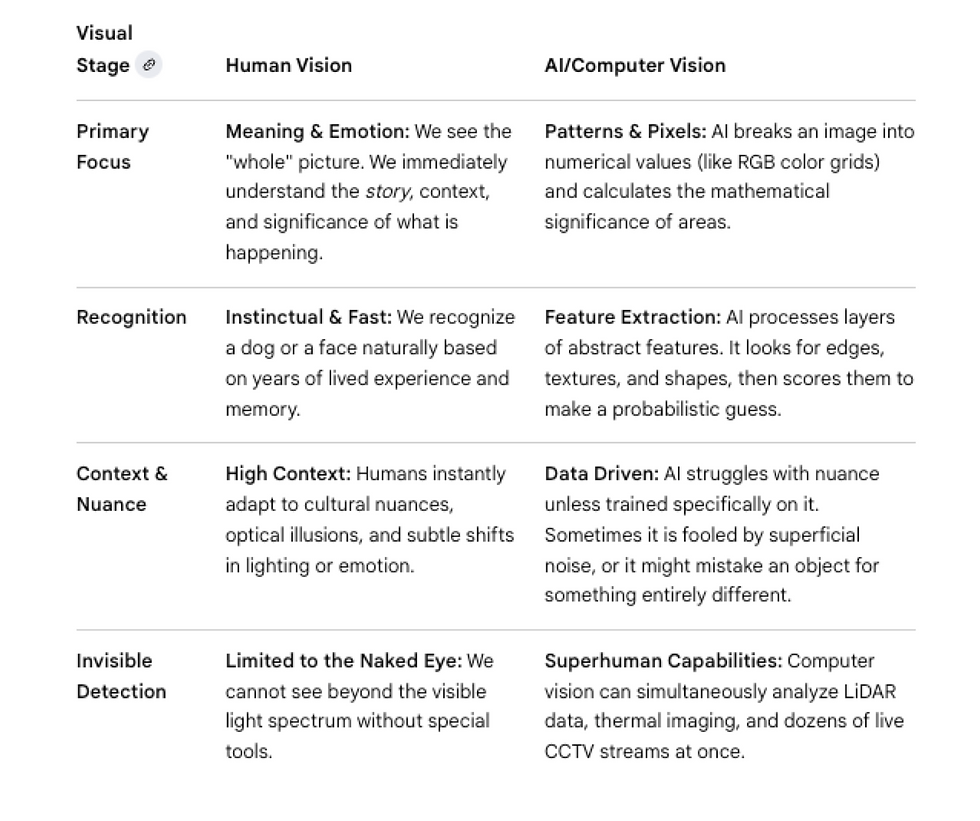
Human Vision versus AI/Computer Vision
Traditional communication strategies operate under the assumption that you can cure a machine-learning model that confuses public consensus with factual truth by simply manufacturing more human agreement.
But AI models do not process human trust, brand posture, or emotional sentiment. They calculate statistical probability, data consistency, and machine legibility across the web.
When an LLM crawls the internet to evaluate a brand, it encounters total data chaos: old articles, messy website code, outdated business directories, unverified Reddit threads, and competitor-framed summaries. If a brand’s core positioning and corporate truths are not hardcoded into the site's underlying infrastructure, the AI will ignore the expensive media placements and tactical storytelling and default to the loudest, cheapest noise in its training loop.
Piling more unstructured text onto an unoptimized website doesn't fix a narrative crisis—it simply forces the AI to formalize human gossip into an undisputed algorithmic summary.
The Reality of the Two Storefronts
As enterprise operations shift rapidly into an agentic future, every modern business MUST now operate two distinct storefronts:
The First Storefront: The polished, human-facing website that corporate teams see, edit, and admire.
The Second Storefront: The highly synthesized, hidden data profile that an AI engine assembles on its own every time a user inputs a commercial AI prompt. That’s the one we focus on.
This second storefront already shapes enterprise trust, consumer choice, and routing of high-value purchases. Yet because it lives in the data layer rather than the copywriting layer, almost no corporate communications team actively manages it.
If an AI engine repeats old hours, quotes wrong services, relies on stale reviews, or blurs a luxury legacy brand with a drugstore alternative, traditional PR levers cannot rewrite the machine's memory, but we can.
Where we are in regard to Automation and Generative AI
Introducing the AI-Facing Business Identity Layer
To bridge this gap, the industry must transition from superficial visibility metrics to a disciplined framework of Algorithmic Integrity. Brands do not need more content volume; they need an explicit, owner-confirmed AI-Facing Business Identity Layer. A source of truth.
An AI-Facing Business Identity Layer can function as a Semantic Layer (a technical framework for organizing business information uniformly) to support unified business logic, or as a Trust Layer (a technology for data validation). It serves as the foundational Single Source of Truth for AI systems, ensuring a consumer gets the right answer about your brand. In this case, it’s technically an authoritative "context layer" (a verified reference for AI responses) rather than a raw "system of record” (a database of historical transactions), but more on that to come.
It translates technical, fragmented data from platforms like an Enterprise Resource Planning (ERP; software that manages business operations), Customer Relationship Management (CRM; software that manages customer interactions), or database into a single, standardized vocabulary for corporate information—such as revenue, churn, products and features, and board members.
It’s a required grounding AI output. Rather than have a large language model (LLM) guess or make up facts, the identity layer grounds them in real-time governed corporate data—just the facts. For AI Agents (autonomous software acting on behalf of users or brands), it’s the authentication and authorization control plane (a system that manages which actions are allowed) that tracks delegated authority, permissions, and audit trails.
Ensuring AI Accuracy
We’re now working closely with our technical partner, the GEO-data infrastructure platform Agntbase, to move past one-time GEO and SEO audits to establish a continuous, machine-readable "Control Room" for enterprise reputation. You can check out its early structure at https://www.agntbase.com.
Uncompromising Entity Disambiguation: Explicitly mapping products, founders, intellectual property, and locations as distinct semantic nodes so that AI models respect clear brand-positioning boundaries (they get your brand right every time). We’re delivering the clear, trusted machine narrative that agencies today are missing.
Defining Safe Agentic Actions: As AI answers evolve into tasks for autonomous AI agents, such as compare, book, and buy. Brands must hardcode explicit boundaries—such as secure API checkout handoffs or human-in-the-loop review triggers—so machines route commerce accurately without improvising.

Information Tech and Where We Are Now
A Log Receipt, Not a Ranking Promise
The ultimate validation of AI engineering isn't a vague ranking promise—it is a technical receipt. By establishing an undisputed data layer (a structured, authoritative database for machines) and auditing server logs, we can now move enterprises away from theoretical guesswork and track exactly when major web crawlers—like GPTBot (ChatGPT’s web crawler), ClaudeBot (Claude’s crawler), and PerplexityBot (Perplexity AI’s crawler)—access and digest in their verified record.
For global agencies and brand guardians, narrative control has a new frontier. Your clients demand to know what the machines are saying. Partner with us and ensure your AI-facing business identity is accurate and optimized. We can develop your infrastructure now and help shape your reputation for the next decade.

Comments